
What Front-end development really means?
Skipping the foundations of frontend development and jumping right into a web framework like Angular is not good in the long run either; that is like memorizing a recipe and repeating it over and over with slight variations when you find a problem that deviates from the recipe, you're lost.


One of the difficulties for new software engineers interested in web development (and especially frontend development) is that, usually in academia, textbooks, and online courses, the focus is put on high-level frameworks and libraries, with the intent to become productive right-way, overlooking many of the foundations and leaving behind knowledge gaps that lead to confusion, misunderstandings and even lack of confidence to continue learning more advanced concepts.
Article series
- The evolution of Frontend Development
- The rise of Single Page Applications
- What Front-end development really means?
- JavaScript Engine and the Event Loop
- JavaScript Programming Paradigms
The case of the library-oriented developer
Skipping the foundations of frontend development and jumping right into a web framework like Angular is not good in the long run either; that is like memorizing a recipe and repeating it over and over with slight variations when you find a problem that deviates from the recipe, you're lost. Have you heard the saying "we must learn to walk before we can run"?. That uncovers a special meaning in Frontend architecture, as we saw in the first post: software architecture represents the design decisions related to overall system structure and behavior, where design decisions and the system structure depends on the knowledge of the system as a whole, including the low-level foundations, libraries just fit in higher levels to get a trade-off in architecture characteristics.
If we go back in time, ten or fifteen years ago, the main focus of web development was in Object-Oriented programming, mostly server-side or back-end, from which we have a great legacy of design patterns and development principles. However, frontend development has grown and taken its path that diverges in a good share from backend, having its patterns and principles and including elements from Function Programming. For these points, it makes sense to get a separate set of foundations for frontend development only that will greatly help us succeed in building robust and reliable web applications.
In this article, we'll focus on the main concepts, technologies, and principles under modern web browsers are built upon, which are particularly important to understand many of the topics we'll cover in future chapters. This might raise the common denominator a little so that slightly greater assumptions are taken later in the book. If you're an experienced developer already, you might find you already have a perfect understanding of all the contents in this chapter, if that's the case, please feel free to skip it.
You can always come back later if something isn't as simple as you thought. If you're not certain you know everything in this article, you can look at the summary at the end which summarizes the important points, if any of those are unfamiliar, it's worth reading the corresponding section in detail.
We started the previous article by reviewing how a web developer would build a Dog Breed application (The evolution of Frontend development) over the years, using different development technologies. Now we'll take a slight step back to see how this web application works, independently of any development library, as the principles and techniques we can use with JavaScript and Web APIs apply for the development of any frontend project, regardless of the web technologies chosen, beyond that, such technologies rely on the foundations we'll study shortly and many of the problems we face in the advanced use of these tools should be solved having a solid understanding of the building blocks of any development tool.
We'll start by looking at the browser runtime environment and its components: The DOM, Web APIs, the layout, and JavaScript engines. Then we'll cover an important mechanism in modern browsers called the Event Loop, which makes it possible to have asynchronous processes for handling concurrent tasks. Finally, we conclude this chapter (next articles in the series) with a detailed examination of the JavaScript programming language from an architectural point of view.
What are the front-end and back-end?
Usually, when we talk about web applications, we refer to software programs hosted in Web Servers. We use a web browser to hit a URL, that is translated into an IP address (DNS resolving) to access those programs or applications. So we connect to the server and then load the program (or part of it) in pieces of HTML, JavaScript, and CSS code, that renders the user interface and allows subsequent information exchange between a web browser (client) and server using a communication protocol like HTTP.

We can say that such an application is distributed between the web browser and the web server, as shown in the figure above. The application works by a series of requests sent by the client (originated by interactions from the user) and the responses that the server sends back in return. If we remove any of the two components, the application wouldn't do anything useful from the user's perspective.
Even though a web application can be seen as a distributed system along with a web browser and a web server, each component runs in a separate CPU process, one in the user's mobile or desktop computer and the other in the server computer. Each of these processes has independent resources like memory and processor time, the only thing shared is the information exchange by request/response interactions. Then, naturally, each component can be developed independently one from another, only agreeing on a design contract in the form of an API exposed by the server (back-end) and the client (front-end). In this chapter and the rest of the book, we'll focus on the front-end side of back-end applications and the communication established by the APIs between them both.
Anatomy of a Web Browser
The distributed nature of web applications is one of the characteristics that tell them apart from other software programs, like classic (offline) desktop or embedded applications. However, nowadays embedded devices have internet connectivity (Internet of Things, a popular concept involving devices (things) interconnected via the Internet), similarly many desktop applications talks to web servers from desktop computers, what in some sense, make them front-end applications. But still, there is another characteristic that web applications running on web browsers have that makes them different, at least from the development point of view, and that is the runtime environment.
Before the beginnings of the World Wide Web and the first web browsers, developers used to write desktop applications in a run-time environment that resembles the figure below. These desktop applications compile into machine code and run directly in the Central Processor Unit (CPU), having access to lower layers as the peripherals and the framework APIs, which in turn allows access to the underlying operating system (kernel) and do things like allocating dynamic memory (RAM), direct access to storing and reading files from hard drive, low-level access the mouse or keyboard events, among other things.

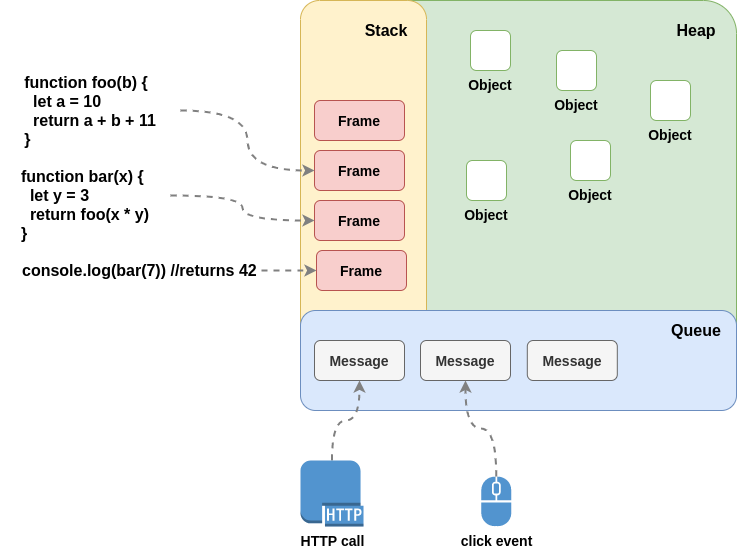
Coming back to web browsers, the run-time of front-end applications inside of them are quite different from desktop applications. The figure below shows a simplified model based on the abstraction layers. In contrast with the model in figure 2, there is no direct access to the hard drive, peripherals of the possibility to allocate dynamic memory, this is because this is an interpreted runtime, meaning that the application is rather interpreted by a framework or engine than compiled into machine code. In our case, the JavaScript language is interpreted by a JavaScript Engine inside the browser, while access to peripherals and communication to the outside world is also provided by the browser via a combination of Web APIs (discussed in the next article).

On the other hand, we have two distinct interfaces to interact with the runtime environment, besides the JavaScript programming language, used to define dynamic behavior, we also have HTML and CSS to define presentation in the form of style of the web page using the Document Object Model (DOM) which is ultimately displayed in the user's device screen.
We'll continue analyzing the components in the layer of figure 3 in the following sub-sections.
The Document Object Model (DOM)
The Document Object Model is the central component that connects the Layout Engine with the application code, third-party libraries, the Web APIs, and the JavaScript Engine. It is both of two things, a model representing the document or web page structure, and an API to make queries on that structure and commit modifications. Strictly talking, the DOM as the API is part of Web APIs, and the Web APIs also contain models for other tasks than manipulation of the page structure and style, but traditionally, a distinction is made between the DOM and other Web APIs, as the DOM is the primary interface a developer uses to build a web application, and as we'll see shortly, web frameworks add an abstraction layer to simplify many of the tasks related to DOM manipulation as one of the main design concerns.
Both, Web APIs and the DOM are standards defined by the World Wide Web Consortium (W3C) to provide seamless implementations from different web browser vendors that are cross-platform compatible, in other words, the same web application can run in Google Chrome or Mozilla Firefox without any logic handling (in practice, this logic keeps at a minimal amount). This is possible thanks to the dependency inversion principle (One of the SOLID principles proposed by Robert C. Martin, concrete components should depend on abstractions, inverting the dependency flow) taken in the internal architecture of a web browser. Figure 4 shows a dependency flow from more concrete at the bottom, to more abstract at the top, the JavaScript and Layout Engines are the most low-level components, which depends on the Web APIs and DOM interfaces, allowing them to have different implementations between vendors and even between versions without breaking cross-compatibility and keeping backward compatibility.

In contrast, higher-level components as the Application code and Third-party libraries have a regular (not inverted) dependency flow with the DOM and Web APIs. In particular, libraries and frameworks have evolved over the years to provide an abstraction layer for the application code to enable more complex functionality with less amount of code hiding the bellow implementation details, an idea we explored in the previous chapter when we talked about web development using modern libraries as depicted in the model of figure 5.
Several of the patterns have emerged over the years on frontend developers deal with the problem of efficient and maintainable DOM manipulation, and live in the abstraction layer lying between the application code and the Web APIs. Patterns such as Model View View-model or the Virtual DOM are good representatives of this category and we'll devote a good amount of time studying them in future articles in this series.
Layout Engine
The layout engine or rendering engine or also the browser engine is a software component inside the web browser responsible for parsing HTML documents in combination with Cascading Style Sheets to produce a visual representation on screen.
Each browser may use a different engine like Chrome and Opera uses Blink, Firefox uses Gecko, Edge use EdgeHTML and Apple Safari uses WebKit. Depending on the layout engine, some general use CSS properties might look different or not supported by some browsers, and specific properties for the engine might be needed, for example, WebKit has several properties with the prefix _-webkit-_. To solve this problem a common pattern is to add an abstraction layer in the form of CSS libraries as Bootstrap or Material UI, that apply the right properties depending on the detected layout engine. We'll study some of those patterns in later chapters.
In the next article, we'll continue analyzing Web APIs, JavaScript Engine, and the JavaScript programming language to get solid foundations to better understand several architecture patterns that are built upon those.