
The rise Single Page Applications


Moving ahead to the early 2010s, we witnessed another important change in the way web applications are designed. Traditionally, the flow to get a web page rendered in the browser consisted of making an initial request from a web server, that in turn gives back the complete HTML page using a predefined template, and any subsequent request repeats every time, making the browser reload the whole page, as shown in the next figure,
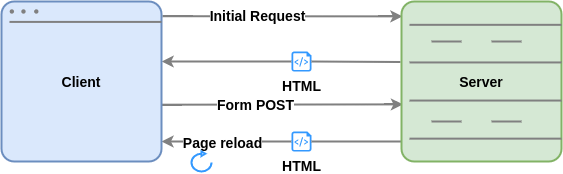
That style of architecture is commonly known as Multi-page Application, as the interchange between client and browser consists of multiple whole web pages, making it good for Search Engine Optimization (SEO). A variant of this style is static websites, where the web pages are stored and delivered to clients as they are, without any manipulation by the server application or the client application layer. A popular derived approach is to use static website generators, as they are fast and simple to develop web pages for blogs or news sites, using predefined templates and themes, an idea popularized by Netlifly with its coined concept of Jamstack (JavaScript + API + Markup).
Article series
- The evolution of Frontend Development
- The rise of Single Page Applications
- What Front-end development really means?
- JavaScript Engine and the Event Loop
- JavaScript Programming Paradigms
Nevertheless, as the JavaScript engines and computer processing power improved, it became evident that it is not necessary to fetch a complete HTML page after the initial request, but instead, use AJAX calls to fetch only the data in some kind of document (like JSON or XML to say some) and let the underlying framework to dynamically modify the DOM to reflect the changes derived from this data. This process is illustrated in the diagram below and is known as Single Page Applications, or simply SPA. Among other benefits, it reduces the amount of data transferred between the client and the server, thus providing a faster user experience mimicking a desktop application's look and feel.
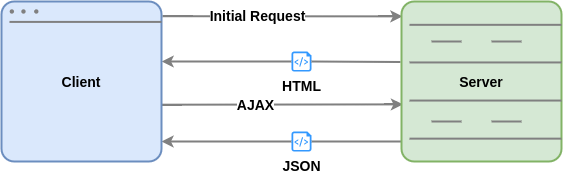
Other variants of the SPA style have emerged more recently, usually, a hybrid of the Multi-page and Single page architectures, combining the idea of Server Side Rendering (SSR) to deliver a pre-rendered web application that contains segments of JavaScript from a SPA framework (dehydrated) and then is loaded in the client-side (re-hydrated) to work as a SPA. Some successful projects like Next.js, GatsbyJS (using React) and Nuxt.js (using Vue) follow this hybrid architecture style and make a trade-off in the advantages of fast page transitions from SPA and SEO friendly approach in SSR.
In addition to these architecture styles, a set of Web APIs known as Progressive Web Applications has emerged to the aid of building better web applications in terms of user experience and capabilities, having standard means for dynamic and static caching, offline work, server update notifications, installation like a native application and other features that we'll study in further chapters.
The new era of Component-based design
With the rise of SPAs, a development paradigm became popular, splitting the different parts conforming a web page into small and independent components, each one representing a set of visual elements that provide specific functionality. Many modern development frameworks and libraries like React, Vue, or Angular follow this scheme.
Better DOM Manipulation
Nonetheless, each framework/library has its particular approach to make use of the components following a design philosophy to solve a specific design concern. Projects like React and Vue, for example, use a concept of a Virtual DOM to efficiently link the state model of a component (or properties) with DOM elements and update (or react) only to changes in the properties with the bound elements in the Real DOM, leaving others unchanged, using a diffing algorithm, as shown in the next diagram. An approach like this shines in scenarios where there are many changes in a page happening concurrently, as it happens in social media websites, where this technique was born.
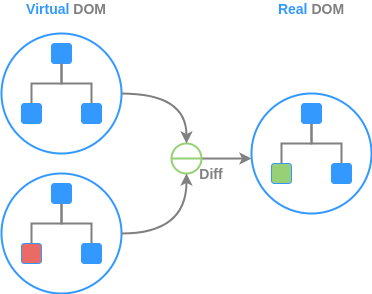
React also uses a technique, in combination with the Virtual DOM, to bind the component's properties with the DOM elements, using an abstraction where the HTML is written inside of JavaScript code, a technique also known as JavaScript XML or simply JSX.
This use of HTML inside JavaScript is exemplified in the listing below, with an implementation of the Dog Breeds application using this time React (This code listing is written in React version 17) to define the application as a functional component that returns the HTML structure of the page.
function App() {
const [breeds, setBreeds] = useState([]);
useEffect(() => {
fetch(BREED_URLS.list()).then((res) => res.json())
.then((data) => setBreeds(Object.keys(data.message)));
}, []);
...
return (
<div>
<h3>Dog Breeds</h3>
<div>
<button className="dropdown-button">{selectedBred}</button>
<button className="dropdown-button-list"></button>
</div>
<div className="dropdown-content">
{breeds.map((b) => (<a>\{b\}</a>))}
</div>
<div className="pictures">
{pictureUrls.map((url) => (<img src={url}></img>))}
</div>
</div>
);
}Proper state management with Functional Programming
Using a technique as JSX has the advantage of abstracting away the process to modify the DOM to reflect any change in the component's properties. React goes indeed a step ahead and expresses a change in a component's state as a state hook, that is a functional way to derive a state from an immutable variable assignation, like the assignation of the breeds array to an empty array [], that is only modified using setBreeds() which is a pure function. Likewise, the side effects are handled similarly, the side effect of fetching the breed list from the API is specified here, as the result of the side effect is modifying the breed array.
Inversion of control with OOP
React shines when it comes to efficiently manipulating the DOM and avoiding arbitrary state mutability, but there is still a problem it can't solve (at least only by itself), the separation of concerns between the code functions responsible for making AJAX call (side effects) the code of the component. That's something more appropriate for the Object-Oriented Programming paradigm, which allows to isolate responsibilities into objects and transfer the control between. This idea is the key of the Inversion of Control principle, where the flow of control is inverted from the traditional imperative scheme (like the old JQuery code did), where calls to low-level APIs are explicit. Instead, the control is handled by a framework and the application code defines the segments of code that are more specific for the task performed. Following thus another related principle, known as the dependency inversion principle.
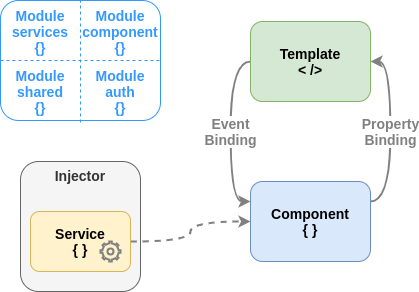
Frameworks like Angular or Vue implement the inversion of control in its architecture style, where there are preferred ways to separate the component logic from the code used in handling side effects, in the form of services. This is illustrated in the diagram above, where there is a diagram representing the typical architecture of an angular application. Component code in JavaScript is separate from the HTML code by using a class with properties and a template, accordingly, but they connect by events and property bindings. On the other hand, the logic to handle, for example, the API call to get the breed list in the Dog Breed application, is implemented as a service, which is injected (dependency injection) into the component at some point the flow of control managed by the framework.
Architecture Problems in Frontend Development
In the previous post, as we followed the example web app of Dog Breeds, we discovered a series of architecture concerns regarding the web development nature of building applications that run in a web browser. Let's summarize these concerns into a classification of patterns.
Patterns for DOM Manipulation
These patterns deal with the problem of linking the application state with the DOM structure in loosely coupled ways the allow both to be modified independently one from another. Examples of this kind of pattern are the JSX syntax in combination with the virtual DOM found in React and Vue frameworks, or the Model-View-ViewModel and related patterns used in frameworks like Angular.
State Management Patterns
The concern of separating the state manipulation from DOM and component lifecycle code is the focus on some kind of patterns created for such a purpose. We saw some examples in this chapter with the use of React hooks, which allows modifying the state of an application and its side effects using functional programming principles. Similarly, other tools like Reactive Extension (RxJS) can help us with useful patterns for handling side effects in synchronous and asynchronous code, improving readability and robustness.
Inversion of Control Patterns
As the complexity and size of codebases increase, it becomes very important to have a project structure that allows sustainable growth while keeping performance (scaling) and maintainability. Inversion of control patterns specializes in this architecture concern, for example, Angular keeps separate modules for each section of a project and uses dependency injection to abstract away the process of creating new instances from application code, improving low coupling and testability.
Another example is the component concept itself, used in many web frameworks (Angular, Vue, React, and several others), that separates whole segments of cohesive HTML, JavaScript, and CSS code into independent units that are managed by the framework in different lifecycle steps of a web page.
What you'll learn in this series
By the time you finish reading this series, you'll understand the following:
- Solid foundations on Frontend architecture concepts and relationship with the DOM and Web APIs
- The architecture styles available for building web applications, their benefits and drawbacks, and when to use them
- DOM Manipulation patterns
- State management patterns
- Inversion of Control patterns
- Distributed web application and development libraries
You'll also be able to do the following:
- Architect a web application using the appropriate style and design patterns
- Choose the right development frameworks and libraries according to functional and non-functional requirements
- Effectively use DOM manipulation patterns to handle model structure and address performance concerns
- Use state management patterns to maintain consistency with an increase in complexity
- Effectively test web applications
- Refactor existing web applications using different technologies and how to make them interoperable with new ones.
Why is Frontend Architecture relevant to you?
If you are a Software Engineering interested in front-end or full-stack development and want to expand your knowledge on the tools used to solve a wide variety of problems building web applications, or perhaps you have specialized in a specific tool or framework and want to discover how other options work and the opportunities that come with it, then this series is for you.
If you are pursuing a role of a Software Architect overseeing different projects, each one implements using different web development technologies, and want to learn how to balance the trade-offs of each technology or technique, getting a deeper context of the reasons behind specific architecture styles and the best use of it, then you'll find valuable information in this series.
In the next article, we'll cover the Core Foundations for building frontend applications, as they are the basis for a scalable and robust architecture.